BeautifulSoup 对象的构造函数签名如下:
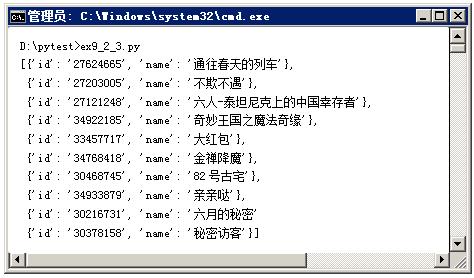
from bs4 import BeautifulSoup soup = BeautifulSoup(markup, "parser", **kwargs)
核心参数有三个:markup, parser, 和一些可选的关键字参数 **kwargs。
markup (必需参数)
这是你想要解析的文档内容,它可以是以下几种类型:
-
字符串 (
str): 这是最常见的方式,直接传入 HTML/XML 文档的字符串。html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three sisters; and their mother...</p> </body></html> """ soup = BeautifulSoup(html_doc, 'html.parser')
-
字节类对象 (
bytes): 如果你从文件或网络读取的是二进制数据(指定了编码),可以直接传入。BeautifulSoup会自动尝试解码。 (图片来源网络,侵删)
(图片来源网络,侵删)# 假设从文件中读取的二进制数据 with open('index.html', 'rb') as f: bytes_data = f.read() soup = BeautifulSoup(bytes_data, 'html.parser') -
文件类对象 (
file-like object): 任何实现了read()方法的对象都可以,比如打开的文件对象,这在处理大文件时非常高效,因为它不会一次性将整个文件读入内存。with open('index.html', 'r', encoding='utf-8') as f: soup = BeautifulSoup(f, 'html.parser')
parser (必需参数)
这个参数告诉 BeautifulSoup 使用哪种解析器来处理你的 markup。BeautifulSoup 本身是一个解析器框架,它依赖于第三方库来完成实际的解析工作。
选择合适的解析器非常重要,因为它们的性能、容错能力和特性各不相同。
a. 内置解析器: 'html.parser'
- 来源: Python 标准库,无需额外安装。
- 优点:
- 无需安装,开箱即用。
- 速度相对较快。
- 与 Python 版本绑定紧密。
- 缺点:
- 容错性较差,对于格式不规范的 HTML 文档可能会解析失败或解析出奇怪的结果。
- 功能可能不如第三方库强大。
使用示例:
soup = BeautifulSoup(html_doc, 'html.parser')
b. 第三方解析器: 'lxml'
这是 强烈推荐 的解析器,是目前功能最强大、性能最好的选择。
- 来源: 第三方库,需要提前安装。
pip install lxml
- 优点:
- 速度极快: 是
html.parser的数倍甚至数十倍。 - 容错性强: 能很好地处理格式混乱、有错误的 HTML 文档。
- 功能强大: 支持强大的 XPath 选择器(可以通过
soup.xpath()使用)。
- 速度极快: 是
- 缺点:
- 需要额外安装。
- 依赖于 C 库,在某些环境(如某些受限的虚拟环境)下编译可能比较麻烦。
使用示例:
soup = BeautifulSoup(html_doc, 'lxml')
c. 第三方解析器: 'html5lib'
这个解析器追求 100% 符合 HTML5 标准。
- 来源: 第三方库,需要提前安装。
pip install html5lib
- 优点:
- 容错性最强: 它会尝试修复和纠正你文档中的所有错误,生成一个“完美”的文档树。
- 最符合标准: 严格按照 HTML5 规范解析。
- 缺点:
- 速度最慢: 因为它要尽力修复错误,所以解析过程非常耗时。
- 需要额外安装。
使用示例:
soup = BeautifulSoup(html_doc, 'html5lib')
关键字参数 (**kwargs)
这些是可选参数,用于控制解析过程的行为。
a. features
这个参数的作用和第二个位置参数 parser 完全一样,如果你想把解析器作为关键字参数传入,可以使用它。
# 这两种写法是等价的 soup1 = BeautifulSoup(html_doc, 'lxml') soup2 = BeautifulSoup(html_doc, features='lxml')
b. builder
这是一个更底层的参数,允许你直接传入一个 TreeBuilder 对象,而不是通过名称来指定解析器,通常你不需要直接使用它,除非你在进行高级定制或开发自己的解析器。
c. parse_only
这是一个非常有用的参数!它允许你只解析文档的一部分,从而大大提高解析速度和内存效率,尤其是在处理非常大的 HTML 文档时。
它的值是一个 SoupStrainer 对象。SoupStrainer 可以让你根据标签名、属性、CSS 选择器等条件来指定需要解析的部分。
示例: 假设我们只关心 <body> 标签里的内容。
from bs4 import SoupStrainer
# 只解析 body 标签及其所有后代
only_body = SoupStrainer('body')
# 原始文档
html_doc = """
<html><head><title>Ignore me</title></head>
<body>
<p>This is the only part I care about.</p>
<div>And this too.</div>
</body>
</html>
"""
# 创建 soup 对象时,只解析 body 部分
soup = BeautifulSoup(html_doc, 'html.parser', parse_only=only_body)
# soup 中已经没有 <html> 和 <head> 标签了
print(soup.prettify())
# 输出:
# <body>
# <p>
# This is the only part I care about.
# </p>
# <div>
# And this too.
# </div>
# </body>
d. from_encoding
当 markup 是字节流 (bytes) 时,这个参数可以显式指定文档的编码。BeautifulSoup 无法自动检测编码,或者检测错了,你可以用它来手动指定。
# 假设 bytes_data 是 GBK 编码的中文网页 soup = BeautifulSoup(bytes_data, 'lxml', from_encoding='gbk')
总结与最佳实践
| 解析器 | 安装 | 速度 | 容错性 | 推荐场景 |
|---|---|---|---|---|
'html.parser' |
无需安装 | 中等 | 较差 | 快速脚本、环境受限无法安装第三方库时 |
'lxml' |
pip install lxml |
最快 | 强 | 绝大多数情况下的首选,性能和容错性兼备 |
'html5lib' |
`pip install html5lib** | 最慢 | 最强 | 处理非常混乱、难以修复的 HTML,或需要 100% 标准兼容性时 |
核心建议:
- 首选
'lxml': 除非有特殊原因,否则总是优先选择lxml,它的性能和可靠性是最好的。 - 处理大文件用
parse_only: 如果你只需要从巨大的 HTML 页面中提取一小部分信息,务必使用parse_only参数来提升性能。 - 明确指定编码: 如果处理的是二进制数据且编码可能不明确,使用
from_encoding参数可以避免很多麻烦。 - 优雅降级:
lxml因为环境问题无法安装,html.parser是一个不错的备选方案。html.parser也解析不了,再考虑html5lib。


