REOPEN 不是一个独立的参数,它是 ALTER DATABASE RECOVER ... 命令中的一个子句,它用于控制 Data Guard 的日志应用进程在遇到特定错误时的行为。
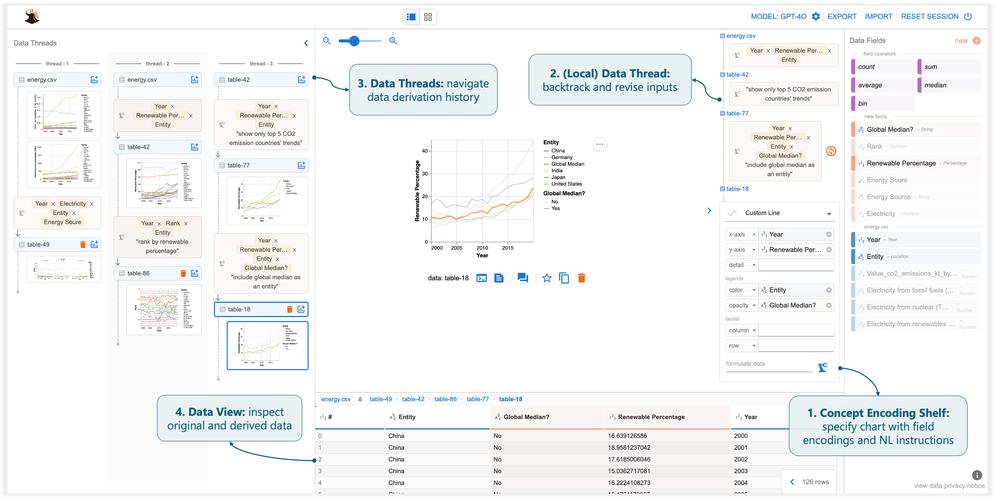
核心概念:REOPEN 是什么?
REOPEN 子句用于配置 Data Guard 的 Managed Recovery Process (MRP) 或 Fast-Start Failover (FSFO) Observer 在尝试从备用数据库应用重做日志时,如果遇到 I/O 错误,应该等待多长时间后再重试。
它定义了在日志应用因物理问题(如磁盘空间不足、网络中断、文件损坏)而失败后,“重试”这个动作的等待时间。
为什么需要 REOPEN?
想象一下这个场景:
- 你的备用数据库正在通过 MRP 进程应用来自主库的重做日志。
- 由于某种原因,备用数据库上的归档日志目录满了,无法写入新的归档日志。
- MRP 进程尝试应用下一个日志块时,发现写入失败,于是报错并停止。
REOPEN 就派上用场了,它会告诉 MRP 进程:“别急着放弃,等一下,然后我们再试一次。” 这给了管理员宝贵的时间去解决问题(比如清理磁盘空间),而不会导致整个日志应用进程崩溃,从而避免了不必要的、耗时的进程重启。
REOPEN 的语法和工作原理
REOPEN 通常在启动或重新配置日志应用进程时使用。
语法
ALTER DATABASE RECOVER [MANAGED STANDBY DATABASE] USING CURRENT LOGFILE [DISCONNECT [FROM SESSION]] [NORETURN];
虽然 REOPEN 是 RECOVER 命令的一部分,但它经常与 MANAGED STANDBY DATABASE 一起使用,以实现自动化管理。
常用命令示例
启动 MRP 进程并设置 REOPEN
这是最常见的用法,你可以在启动 MRP 时指定 REOPEN 的延迟时间(单位为秒)。
-- 启动 MRP 进程,并在遇到 I/O 错误后等待 300 秒(5分钟)再重试 ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT FROM SESSION REOPEN 300;
修改现有 MRP 进程的 REOPEN 设置
MRP 进程已经在运行,你可以通过以下命令来动态修改其 REOPEN 值。
-- 将当前 MRP 进程的 REOPEN 值修改为 600 秒(10分钟) ALTER DATABASE RECOVER MANAGED STANDBY DATABASE REOPEN 600;
查看 REOPEN 的当前值
你可以查询 V$MANAGED_STANDBY 视图来查看当前日志应用进程的 REOPEN 设置。
SELECT PROCESS, STATUS, REOPEN_SECS FROM V$MANAGED_STANDBY; -- 输出示例: -- PROCESS STATUS REOPEN_SECS -- --------- ------------ ------------ -- MRP0 APPLYING_LOG 300
REOPEN 的关键参数详解
REOPEN 子句本身可以接受一个可选的整数参数,这个参数就是重试间隔(秒)。
ALTER DATABASE ... RECOVER ... REOPEN- 如果指定了
REOPEN但没有跟上数字(REOPEN),则使用默认的重试间隔,在 Oracle 10g 及更高版本中,默认值是 300 秒(5分钟)。 - 如果指定了
REOPEN n(REOPEN 60),则重试间隔为n秒。 - 如果指定了
REOPEN 0,则表示不重试,MRP 进程在遇到 I/O 错误后会立即终止,这在某些自动化脚本中可能有用,可以快速失败并触发告警。
- 如果指定了
REOPEN 的适用场景和不适用场景
适用场景(推荐使用)
-
非关键性、暂时性的 I/O 错误:
- 备用数据库的临时磁盘空间不足(
ORA-27059)。 - 网络抖动导致无法连接到 NFS 或 ASM 磁盘组。
- 季度性磁盘清理任务导致短暂的空间满。
在这些情况下,
REOPEN可以让 MRP 进程“容忍”这些错误,等待问题解决后自动恢复,提高了 Data Guard 的高可用性。
- 备用数据库的临时磁盘空间不足(
-
自动化运维环境:
- 在无人值守的灾备中心,
REOPEN提供了一个缓冲机制,避免了因微小故障而触发告警或手动干预,让系统有自我修复的能力。
- 在无人值守的灾备中心,
不适用场景(应谨慎使用或避免)
-
逻辑错误:
REOPEN只对物理 I/O 错误有效,如果错误是由于逻辑问题引起的,例如日志序列号不连续(ORA-00310)、日志损坏(ORA-00313)等,REOPEN不会起作用,MRP 进程仍然会失败并停止,这类问题需要管理员介入,通过解决数据冲突或恢复损坏的日志来修复。
-
主库与备用库数据永久不一致:
- 如果主库执行了不可逆的操作(如
DROP TABLE),而备用库尚未应用,那么当 MRP 应用到该日志时,会因找不到对象而报错。REOPEN的重试只是重复应用同样的错误日志,无法解决问题。
- 如果主库执行了不可逆的操作(如
-
需要立即告警的严重故障:
- 如果磁盘阵列彻底损坏或网络链路完全中断,
REOPEN只会让 MRP 进程无谓地等待,在这种情况下,你可能希望进程立即失败,以便监控系统快速发出严重告警,可以设置REOPEN 0或不设置REOPEN(依赖默认值)。
- 如果磁盘阵列彻底损坏或网络链路完全中断,
最佳实践建议
- 设置合理的默认值:在大多数生产环境中,将
REOPEN设置为 300 到 600 秒(5到10分钟) 是一个不错的选择,这个时间窗口足够管理员响应常见的临时性问题。 - 监控与告警:不要仅仅依赖
REOPEN,必须配置完善的监控和告警机制,当V$MANAGED_STANDBY视图中出现ERROR状态的进程时,即使有REOPEN,也应该触发告警,提醒管理员检查根本原因。 - 文档化配置:在你的 Data Guard 配置文档中明确记录下
REOPEN的值,并说明设置该值的理由,方便团队成员理解和维护。 - 测试:在生产环境应用任何配置更改之前,务必在测试环境中验证
REOPEN的行为是否符合预期。
| 特性 | 描述 |
|---|---|
| 本质 | ALTER DATABASE RECOVER ... 命令的一个子句,不是独立参数。 |
| 功能 | 控制 MRP 进程在遇到 I/O 错误后的重试等待时间。 |
| 语法 | REOPEN [n],n 为等待秒数,默认为 300 秒。 |
| 目的 | 提高备用数据库的可用性,使其能够容忍短暂的、非致命的 I/O 故障。 |
| 适用错误 | 物理I/O错误,如磁盘空间满、网络临时中断。 |
| 不适用错误 | 逻辑错误(如日志损坏、序列号错)或数据不一致。 |
| 最佳实践 | 设置合理值(如300-600秒),并配合完善的监控告警系统。 |
理解并正确配置 REOPEN 是构建一个健壮、高可用的 Oracle Data Guard 环境的重要一环,它是在“自动恢复”和“快速失败告警”之间取得平衡的关键工具。


