- 大数据是燃料:它为人工智能提供了前所未有的海量、多样、高质量的数据。
- 人工智能是引擎:它利用强大的算法和模型,从这些“燃料”中提炼出价值,实现智能化。
下面我将从几个层面详细阐述大数据与人工智能(尤其是其核心——算法)之间的关系。
核心关系:为什么大数据对人工智能至关重要?
传统的人工智能研究受限于数据量,模型难以学习到复杂世界的规律,大数据的出现彻底改变了这一点,其重要性体现在:
-
解决“数据饥饿”问题:以深度学习为代表的现代AI模型,尤其是深度神经网络,拥有数百万甚至数十亿个参数,要让这些参数被有效“训练”并学会识别模式、做出预测,需要极其庞大的数据集,没有大数据,这些复杂模型就是“空中楼阁”,无法发挥其威力。
-
提升模型的泛化能力:模型在训练数据上表现好不等于在实际中表现好,大数据包含了更广泛、更多样化的场景和案例,能让模型学习到更本质、更普适的规律,从而在从未见过的新数据上也能做出准确的判断(即泛化能力强)。
-
发现隐藏的复杂关联:世界是复杂的,变量之间的关系往往是非线性的、多层次的,小数据样本可能只揭示表面的关联,而大数据则能让AI算法通过统计学习,发现人类难以察觉的深层洞察和因果关系。
 (图片来源网络,侵删)
(图片来源网络,侵删) -
支撑个性化与实时决策:无论是推荐系统(如抖音、淘宝)、智能广告投放还是自动驾驶,都需要基于个体用户的实时行为数据进行即时决策,这背后是持续不断产生的大流量的数据,支撑着AI算法的动态优化。
大数据如何驱动人工智能算法的演进?
大数据不仅让现有算法变得更强,还催生了全新的算法范式。
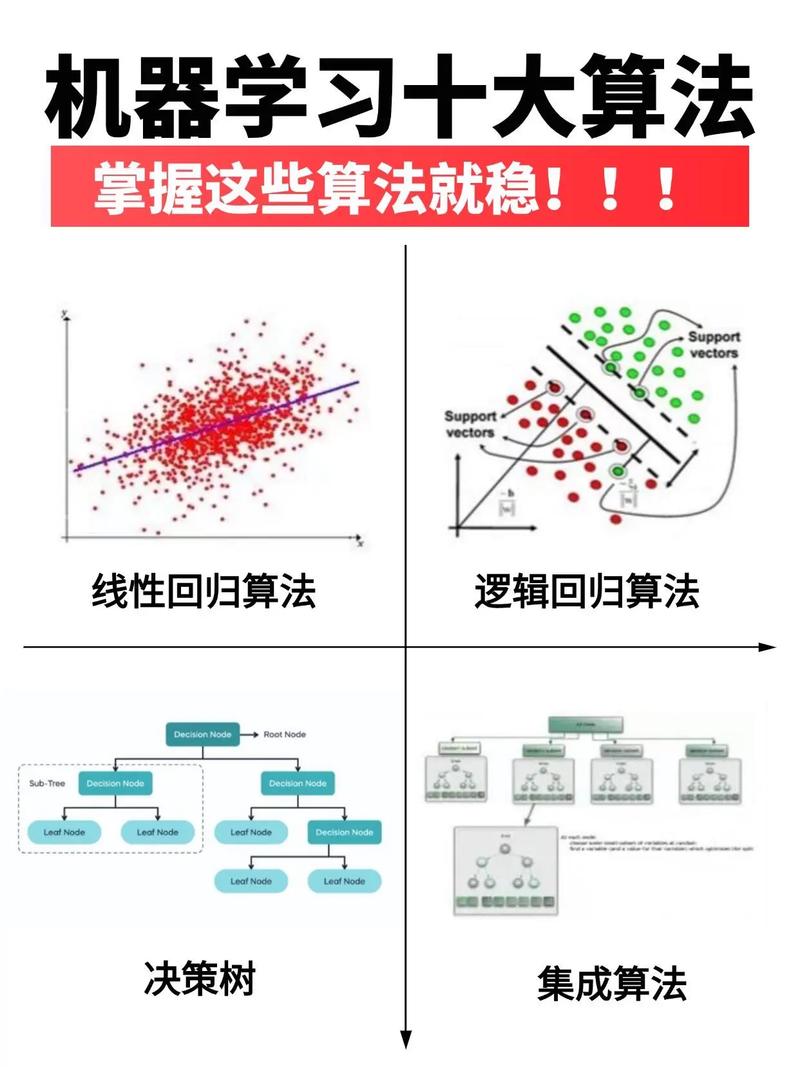
传统机器学习算法的规模化应用
像决策树、支持向量机、逻辑回归、K-Means聚类这些经典算法,在处理小数据时效果有限,但在大数据的加持下,它们通过分布式计算框架(如Hadoop, Spark)被并行化处理,能够处理TB甚至PB级别的数据,在商业应用中依然非常有效。
- 例子:
- K-Means聚类:对数亿用户进行分群,以实现精准营销。
- 逻辑回归:在金融风控中,分析海量用户数据,预测其违约概率。
深度学习算法的崛起
深度学习是大数据时代最耀眼的明星,其核心思想是通过构建深层神经网络,自动从数据中学习特征。

- 卷积神经网络:擅长处理图像数据,正是因为有了ImageNet这样包含数百万张标注图片的大数据集,CNN才在图像识别任务上取得了突破性进展,并催生了人脸识别、自动驾驶视觉系统等应用。
- 循环神经网络 / LSTM / Transformer:擅长处理序列数据(如文本、语音),互联网上产生的海量文本(如新闻、评论、书籍)和语音数据,为训练这些模型提供了“养料”,这直接导致了机器翻译、智能客服、情感分析、ChatGPT等大语言模型的诞生。
- 生成对抗网络:通过在大数据集上进行对抗训练,可以生成以假乱真的图像、音频和视频。
新一代AI算法的探索
随着数据维度的爆炸式增长(一个用户在电商网站的行为数据可能有数千个维度),传统算法遇到了瓶颈,这推动了新算法的发展:
- 图计算:当数据之间的关系(社交网络、金融交易链路、知识图谱)比数据本身更重要时,图算法(如GraphSAGE, GAT)能够在大规模图数据上高效地学习节点和边的表示,用于推荐、反欺诈等。
- 强化学习:在自动驾驶、机器人控制等领域,AI需要通过与环境的不断交互来学习最优策略,大数据(即海量的交互日志和模拟数据)为强化学习提供了宝贵的“试错”经验,加速了策略的收敛。
核心算法类别举例
以下是大数据驱动下的一些关键AI算法类别及其应用:
| 算法类别 | 核心思想 | 大数据的作用 | 典型应用 |
|---|---|---|---|
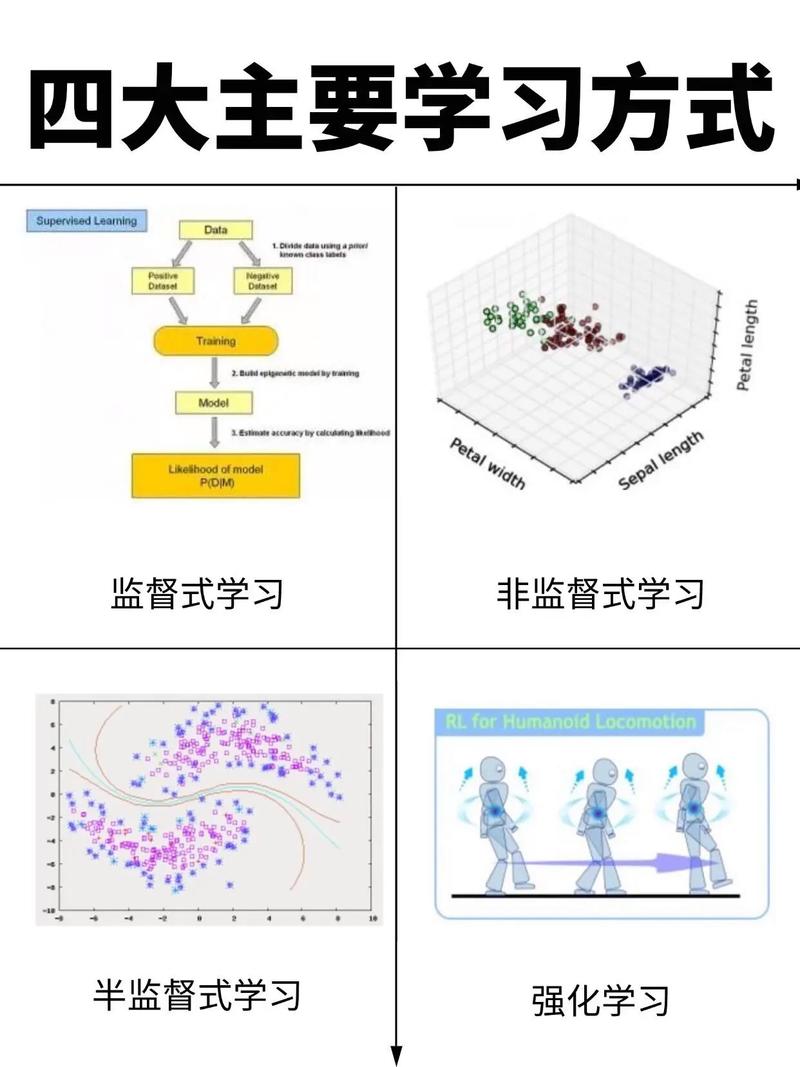
| 监督学习 | 从已标记的数据中学习输入到输出的映射关系。 | 需要海量已标记数据(如“猫/狗”图片、“垃圾/非垃圾”邮件)来训练模型,使其准确识别新模式。 | 图像识别、垃圾邮件过滤、信用评分、疾病预测 |
| 无监督学习 | 在没有标签的数据中发现隐藏的结构或模式。 | 需要海量无标签数据(如所有用户的点击流日志、所有商品描述)来发现自然的分组或异常点。 | 用户分群、异常检测(金融欺诈)、新闻聚类、推荐系统 |
| 深度学习 | 使用多层神经网络自动从数据中学习层次化的特征表示。 | 需要超大规模的数据集来训练数亿级别的参数,避免过拟合,并学习到复杂抽象的特征。 | 语音识别(如Siri)、自然语言处理(如ChatGPT)、计算机视觉(如自动驾驶)、AIGC |
| 推荐系统算法 | 根据用户的历史行为和偏好,预测其可能感兴趣的内容。 | 依赖用户与平台产生的全量交互数据(点击、购买、观看时长等)来精准建模用户兴趣和物品相似度。 | 电商推荐(淘宝)、视频推荐(抖音)、音乐推荐(Spotify) |
| 自然语言处理 | 让计算机理解、解释和生成人类语言。 | 依赖互联网上存在的海量文本数据(网页、书籍、对话)来训练语言模型,学习语法、语义和知识。 | 机器翻译、智能客服、情感分析、文本摘要、大语言模型 |
挑战与未来趋势
大数据与人工智能的结合也带来了新的挑战:
- 数据质量与偏见:大数据不等于好数据,如果训练数据中存在偏见(如种族、性别偏见),AI模型会学习并放大这些偏见,造成不公平的决策。
- 数据隐私与安全:大数据往往包含大量个人敏感信息,如何在利用数据的同时保护用户隐私是一个巨大的技术、法律和伦理挑战(联邦学习、差分隐私等技术应运而生)。
- 算法的可解释性(黑箱问题):深度学习等复杂模型虽然效果好,但其决策过程难以解释,在金融、医疗等高风险领域,无法解释的决策是难以接受的。
- 算力与能耗成本:训练大规模AI模型需要巨大的计算资源和电力消耗,成本高昂且不环保。
未来趋势:
- 小样本/零样本学习:研究如何让AI模型从极少量的数据中甚至不需要数据就能学习,减少对大数据的绝对依赖。
- 多模态学习:将文本、图像、声音、视频等多种类型的数据融合在一起进行学习,让AI的认知更接近人类。
- AI for Science (科学智能):利用AI算法加速科学发现,例如在材料科学、药物研发、基因测序等领域,通过分析海量实验数据来预测新物质或新蛋白结构。
- 可信赖AI:致力于开发更公平、透明、安全和可靠的AI系统。
大数据是人工智能的基石,而人工智能是解锁大数据价值的关键。 它们共同构成了一个正向循环:数据越多,AI模型越智能;AI越智能,能处理和分析的数据就越多,产生的价值也就越大,理解它们之间的协同关系,是把握当前和未来科技发展趋势的核心。


