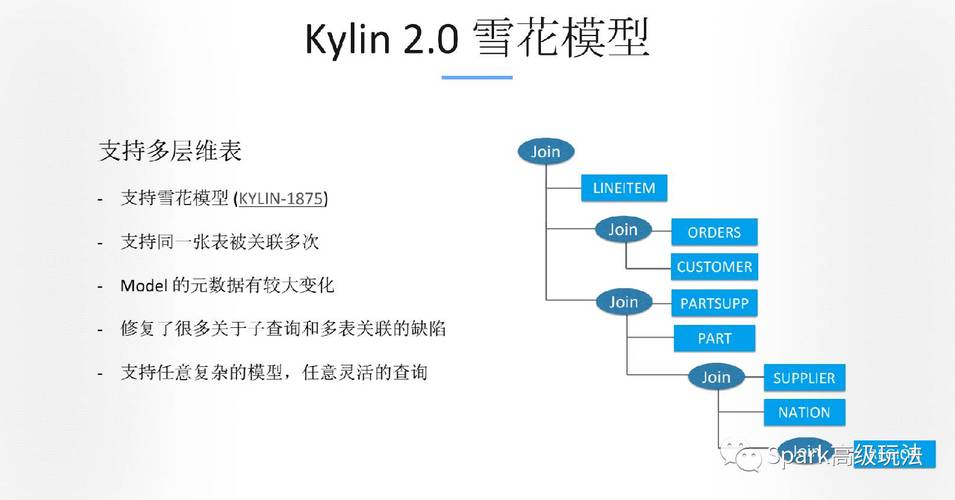
系统级配置
系统级配置主要通过修改 kylin.properties 文件来调整,这个文件位于 Kylin 安装目录的 conf 文件夹下(/opt/apache-kylin-<version>/conf/kylin.properties)。
(图片来源网络,侵删)
核心配置项
| 参数名 | 默认值 | 说明 | 调优建议 |
|---|---|---|---|
kylin.server.mode |
SERVER |
Kylin 的运行模式,可选值:SERVER, QUERY, JOB。 |
- SERVER: 标准模式,所有功能都可用。- QUERY: 仅查询模式,不构建 Cube,适合只读场景。- JOB: 仅任务模式,只负责构建 Cube,适合与前端分离部署。 |
kylin.metadata.url |
jdbc:sqlite:/metadata |
元数据存储的 JDBC 连接串。 | 关键配置,默认使用 SQLite,仅适合开发和测试,生产环境必须使用 PostgreSQL 或 MySQL,格式如:jdbc:postgresql://localhost:5432/kylin_db。 |
kylin.storage.url |
hdfs://localhost:8020/kylin |
Cube 数据存储的 HDFS 路径。 | 关键配置,确保 HDFS 路径存在且 Kylin 有权限读写,此路径将存储所有生成的 Cube 文件。 |
kylin.query.router.default-sql-type |
HBASE |
默认查询路由类型。 | 生产环境通常为 HBASE,表示查询会路由到 HBase,设置为 OLAP 表示查询会走 Spark SQL 引擎。 |
kylin.query.concurrent-limit |
20 |
最大并发查询数。 | 根据集群的查询负载能力调整,值太低会导致排队,太高可能导致集群资源耗尽。 |
kylin.job.engine |
mr |
Cube 构建引擎,可选值:mr (MapReduce), spark。 |
关键配置,强烈推荐使用 spark,它在构建速度、资源利用率和容错性上都远超 MapReduce。 |
kylin.job.mr.reduce-num |
1 |
(仅限MR引擎) Reduce Task 的数量。 | 在使用 MR 引擎时,此参数影响构建速度,通常设置为 Cube 中的维度数量 + 1。 |
kylin.job.mr.reduce-input-size |
256MB |
(仅限MR引擎) 每个 Reduce Task 处理的数据量。 | 影响生成的 HFile 大小和数量,可根据 HBase 的 BlockSize 进行调整。 |
kylin.spark.executor-memory |
2G |
(仅限Spark引擎) Spark Executor 的内存大小。 | 关键配置,根据集群可用资源合理分配,需要预留部分内存给 Kylin 本身和操作系统。 |
kylin.spark.executor-cores |
2 |
(仅限Spark引擎) 每个 Executor 的核心数。 | 根据集群的 CPU 资源和任务类型(CPU密集型或IO密集型)调整。 |
kylin.spark.executor-number |
2 |
(仅限Spark引擎) Executor 的总数量。 | 关键配置。Executor总数 = 并行度,这个值决定了 Spark 作业可以并行处理多少个数据分片,直接影响构建速度,公式:Executor总数 = (集群总内存 - 预留内存) / Executor内存。 |
kylin.spark.yarn.queue |
default |
(仅限Spark引擎 on YARN) YARN 队列名称。 | 在多租户环境中,使用队列来隔离和分配资源,防止某个 Cube 构建任务耗尽所有资源。 |
kylin.cube.size.hard.limit |
0 |
Cube 的大小上限(单位:GB)。 | 0 表示无限制,可以设置一个值来防止 Cube 无限增长,超出后构建任务会失败。 |
kylin.query.timeout |
300000 |
查询超时时间(毫秒)。 | 默认5分钟,对于复杂查询,可以适当调大,防止查询因耗时过长而被中断。 |
JVM 配置
JVM 参数在 conf/kylin-env.sh 文件中设置,而不是 kylin.properties。
# 在 kylin-env.sh 中 export KYLIN_JVM_OPTS="-Xms2g -Xmx4g -XX:+UseG1GC -XX:MaxGCPauseMillis=200"
-Xms/-Xmx: JVM 初始和最大堆内存。必须设置成相同值,防止动态调整带来的性能抖动,通常设置为服务器可用内存的 50%-70%。-XX:+UseG1GC: 使用 G1 垃圾回收器,对于大内存的服务器,G1 的性能和停顿时间优于 CMS。-XX:MaxGCPauseMillis: G1 的目标最大停顿时间,单位毫秒。
Cube 和 Job 级别配置
这类配置更精细,可以在 Cube 设计页面或构建任务中指定,它们会覆盖系统级配置。
Cube 设计页面配置
在 Kylin Web UI 中,创建或编辑 Cube 时,可以设置以下高级选项:
- Engine: 选择构建引擎,这里会覆盖
kylin.properties中的kylin.job.engine。 - Reducer Number: (MR引擎) 设置 Reduce 数量。
- Spark Executor Memory / Cores / Number: (Spark引擎) 设置 Spark 相关参数,覆盖系统级配置。
- Shard Number: 控制 HBase 表的 Region 数量,值越大,查询并发能力越强,但写性能会下降,通常根据数据量和查询模式来设置。
- Storage Format: 存储格式,如
HBASE,HBASE2,FILE等。HBASE2性能更好,是推荐的选择。 - Rowkey: 极其重要,一个好的 Rowkey 设计是 Kylin 高性能查询的关键。
- 原则: 将高基数(区分度高)的列放在后面,低基数(区分度低)的列放在前面。
- 示例:
D1:D2:D3:M1(维度1:维度2:维度3:度量),查询时,如果前缀匹配,可以利用 HBase 的Scan而非全表Get,性能提升巨大。
- Aggregation Groups: 聚合组,合理设计聚合组可以显著减少 Cube 的存储空间和构建时间,将经常一起查询的维度放在同一个聚合组中。
- Disabled: 可以临时禁用一个 Cube,使其不参与查询。
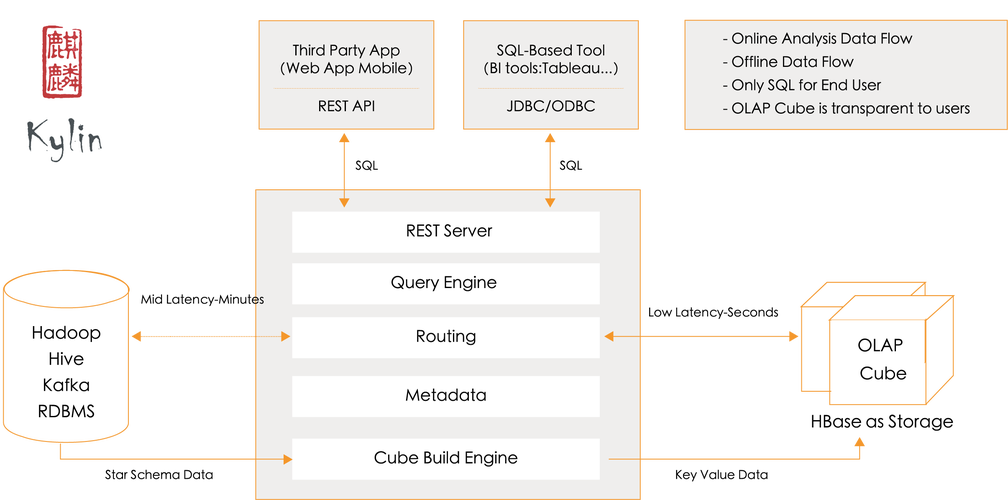
构建任务配置
在提交构建任务时,可以选择不同的构建类型:
(图片来源网络,侵删)
- Build: 全量构建,使用所有源数据重新构建 Cube。
- Incremental Build: 增量构建,只构建新增或变化的数据,要求源数据表必须有时间戳列或类似机制。
- Refresh: 刷新构建,通常用于增量构建,它会先清理旧数据,再构建新数据。
- Merge: 合并构建,将新的 Cube Segment 与旧的合并,适合增量数据量不大时使用。
并行度配置:
在构建任务的高级选项中,可以设置 mapreduce.job.maps (MR) 或 spark.default.parallelism (Spark) 来控制并行度,这是影响构建速度最直接的因素之一。
参数调优思路与最佳实践
-
从系统级配置开始:
- 元数据和存储: 首先确保
kylin.metadata.url和kylin.storage.url指向高性能的数据库和 HDFS。 - 引擎选择: 将
kylin.job.engine设置为spark。 - 资源分配: 根据集群资源,合理配置 Spark 的 Executor 内存和数量 (
kylin.spark.executor-*)。
- 元数据和存储: 首先确保
-
设计高质量的 Cube:
- Rowkey 是灵魂: 花时间测试和优化 Rowkey 设计,对查询性能有决定性影响。
- 聚合组要精简: 避免不必要的维度组合,只保留业务上确实需要的聚合组,每个聚合组都会增加计算量和存储空间。
- 合理选择维度: 不是所有维度都需要放进 Cube,将最常用、能带来最大查询性能提升的维度加入。
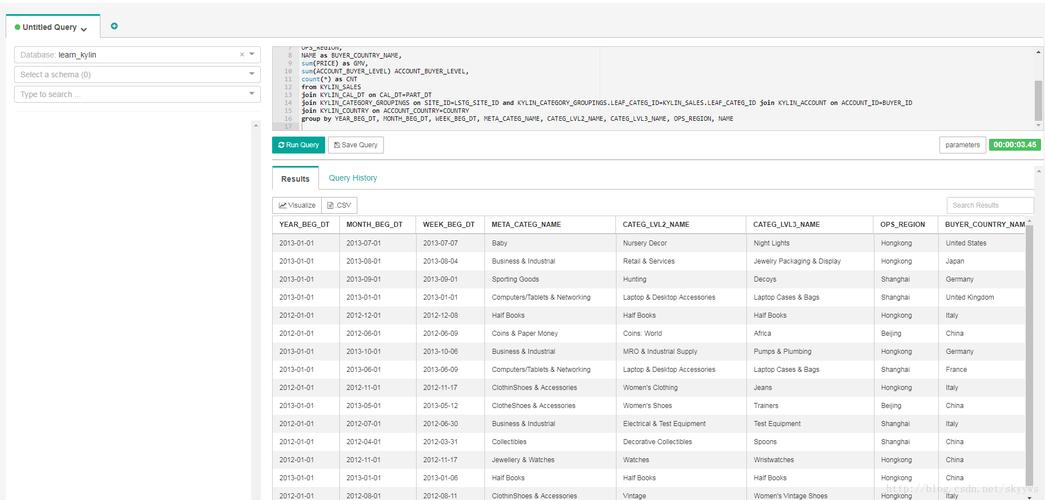
-
监控与调整:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 监控构建: 关注构建任务的日志和耗时,如果构建缓慢,检查 Spark/MR 的资源使用情况(CPU、内存、I/O),考虑增加并行度或分配更多资源。
- 监控查询: 观察查询的响应时间和并发量,如果查询慢,检查是否命中了正确的 Segment,Rowkey 设计是否合理,以及集群资源是否充足。
- 分段管理: 对于大表,采用增量构建或刷新策略,避免每次都全量构建,定期清理过期的旧 Segment。
-
安全与隔离:
- 使用 YARN 队列: 在生产环境中,为 Kylin 配置专用的 YARN 队列 (
kylin.spark.yarn.queue),防止其影响其他业务。 - 设置资源上限: 通过
kylin.cube.size.hard.limit防止单个 Cube 占用过多存储空间。
- 使用 YARN 队列: 在生产环境中,为 Kylin 配置专用的 YARN 队列 (
Kylin 的参数配置是一个系统工程,没有“万能”的配置,最佳配置取决于你的数据规模、查询模式、硬件资源和业务需求。
推荐路径:
- 使用默认配置跑通一个小的 Cube。
- 根据官方文档和最佳实践,调整
kylin.properties中的核心系统参数(引擎、存储、元数据、Spark资源)。 - 重点设计和优化 Cube 的 Rowkey 和聚合组。
- 通过监控和实际业务反馈,持续微调 Cube 级别和任务级别的参数,找到最适合你环境的平衡点。


