将强大的CPU(中央处理器)与专门的硬件加速器(如GPU、FPGA、AI加速芯片等)整合在一起,为AI、HPC(高性能计算)、数据分析等负载提供无与伦比的性能和能效。
(图片来源网络,侵删)
下面我将从几个层面为您全面解读Intel Cup的参数。
核心组成部分
解读Intel Cup的参数,首先要理解它由哪些部分构成,一个典型的Intel Cup平台包含:
- CPU (中央处理器):通常是至强(Xeon)系列,负责通用计算、任务调度、数据预处理等。
- 加速器:这是“Cup”的灵魂,负责执行特定类型的计算密集型任务,常见的加速器有:
- GPU (图形处理器):如Intel Data Center GPU (如Max系列、Flex系列),擅长并行计算,是AI训练和HPC的主力。
- Gaudi (AI专用加速器):英特尔自研的AI芯片,专为深度学习训练设计,对标NVIDIA的A100/H100。
- FPGA (现场可编程门阵列):如Intel Agilex系列,提供硬件级的灵活性,可定制化加速特定算法。
- VPU (视觉处理单元):如Movidius,专注于边缘设备的AI视觉推理。
- 互连技术:连接CPU和加速器的“高速公路”,直接影响数据传输效率,常见技术有:
- PCIe (Peripheral Component Interconnect Express):标准的高速总线。
- CXL (Compute Express Link):一种新兴的开放互连标准,允许CPU和加速器之间共享内存,极大提升性能和降低延迟。
- UMI (Ultra High Bandwidth Memory Interconnect):Gaudi芯片专有的高带宽内存互连技术。
- 软件栈:硬件需要软件来驱动和优化,Intel Cup的软件生态是其核心竞争力之一,包括:
- oneAPI:英特尔的跨架构编程模型,目标是“一次编写,到处运行”(CPU, GPU, FPGA等),避免开发者为不同硬件学习多种语言。
- Intel Extension for PyTorch / TensorFlow:为流行的深度学习框架提供优化,能充分利用Intel硬件的性能。
- Intel HPC Toolkit:提供高性能计算所需的库和工具。
关键参数解读(按硬件类型分类)
理解了组成部分后,我们来看具体的参数,这些参数直接决定了平台的能力。
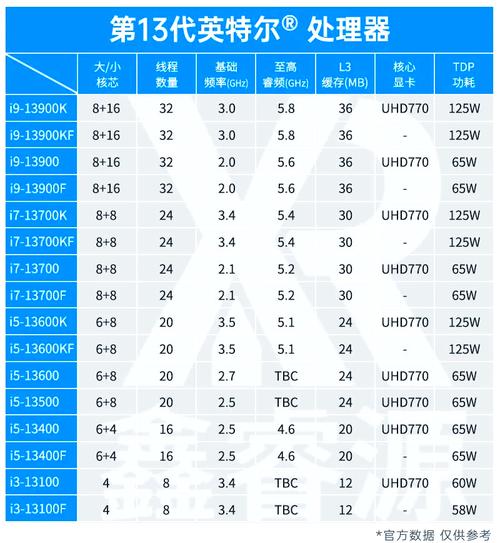
A. CPU相关参数 (以Intel Xeon为例)
- 型号:如
Intel Xeon Platinum 8480+,数字越大,通常定位越高。 - 核心/线程数:
- 核心:物理处理单元的数量,核心越多,并行处理能力越强。
- 线程:通过超线程技术,一个核心可以模拟成两个线程,提升多任务处理能力,32核64线程意味着有32个物理核心,但能同时处理64个任务流。
- 主频 / 最大睿频:
- 主频:CPU的基础运行速度,单位GHz。
- 最大睿频:在特定负载下,核心可以临时达到的最高频率,睿频越高,单核性能越强,对延迟敏感的应用(如某些HPC或推理任务)很重要。
- 缓存:
- L1/L2/L3 Cache:CPU内置的高速内存,缓存越大,CPU能更快地访问常用数据,减少访问主内存的次数,从而提升性能,L3缓存通常是所有核心共享的,对多核性能影响很大。
- 内存支持:
- 通道数:如8通道,意味着CPU可以同时与8个内存条通信,极大提升内存带宽。
- 容量和速度:支持的最大内存容量和内存频率(如DDR5-5600),决定了平台能处理的数据规模和速度。
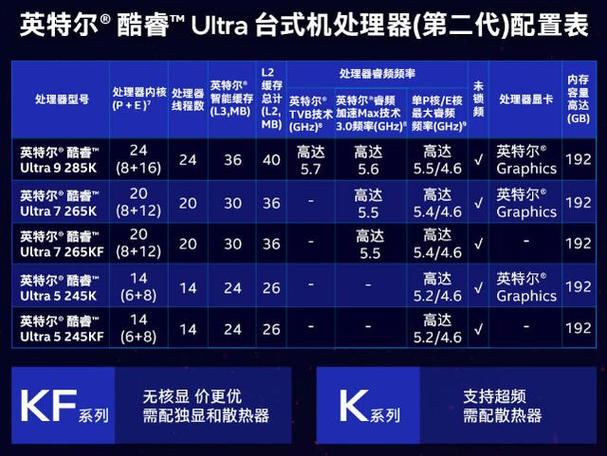
B. 加速器相关参数
Intel Data Center GPU (如Intel Data Center GPU Max 1550)
(图片来源网络,侵删)
- 架构:如
Xe-HP或Xe-HPC,决定了GPU的设计理念和优化方向。 - EU (Execution Units) / XMX Engines:
- EU:是GPU执行并行计算的基本单元,数量决定了并行计算能力。
- XMX Engine:这是Xe架构中专门用于AI矩阵运算的硬件单元,性能远超传统EU,XMX的数量是衡量AI性能的关键指标。
- 内存:
- 类型和容量:如HBM2e(高带宽内存),容量为64GB,HBM提供极高的带宽,对AI训练至关重要。
- 内存带宽:单位是GB/s,如1.5 TB/s,带宽越高,GPU能从内存中“喂”给计算单元的数据越快,性能瓶颈越小。
- 计算性能:
- FP32 (单精度浮点):衡量通用科学计算能力。
- BFLOAT16 (BF16) / FP16 (半精度浮点):衡量AI训练性能,现代AI训练大量使用低精度来加速计算和节省显存。
- INT8 (整数8位):衡量AI推理性能。
- 功耗:单位是TDP (Thermal Design Power),如300W,功耗直接影响散热方案和数据中心的运营成本。
Intel Gaudi (如Gaudi 2)
- 架构:ASIC(专用集成电路),专为AI训练设计,没有传统GPU的图形渲染功能。
- TFC (Tensor Float Core):Gaudi的核心计算单元,专门优化矩阵乘法等AI核心运算。
- UMI (Ultra High Bandwidth Memory Interconnect):这是Gaudi的一大特色,它将8个独立的HBM2e内存池通过高带宽互连在一起,形成一个统一的“超级内存池”,避免了传统GPU中因多张卡互联而带来的性能损失,非常适合大规模的模型训练。
- 计算性能:同样提供BF16/FP16/INT8等算力指标,通常在同等功耗下,其AI训练性能可以媲美甚至超越竞品。
- 网络:内置RoCE (RDMA over Converged Ethernet) 网卡控制器,简化多卡集群的搭建。
平台级参数(综合性能)
当CPU和加速器组合成一个“Intel Cup”平台时,我们还需要关注一些整体性的参数。
- 性能功耗比:这是衡量数据中心效率的核心指标,公式为
性能 / 功耗,一个平台即使性能再高,如果功耗和散热成本过高,也是不划算的,Intel Cup在架构设计上非常重视PPR。 - 互连带宽:指CPU与GPU之间、GPU与GPU之间的数据传输速度,使用CXL或NVLink(如果支持)可以提供比传统PCIe高得多的带宽,对于需要频繁在CPU和GPU之间传输数据的应用(如数据预处理)至关重要。
- 软件生态兼容性:这是决定平台能否被广泛采用的关键。
oneAPI的“一次编写,到处运行”理念就是为了解决传统硬件生态碎片化的问题,如果开发者能轻松地将现有的PyTorch、TensorFlow代码迁移到Intel Cup平台并获得性能提升,那么这个平台就成功了。
如何根据应用选择Intel Cup?
不同应用场景对参数的需求侧重点完全不同。
| 应用场景 | 关键参数 | 侧重硬件 |
|---|---|---|
| AI大模型训练 | FP16/BF16算力、内存带宽、多卡互连技术、软件生态 | Gaudi / Data Center GPU Max |
| AI推理/边缘计算 | INT8算力、功耗、延迟、成本 | VPU (如Movidius)、低功耗GPU |
| 科学计算/CAE | FP32/FP64算力、CPU主频、内存带宽 | Xeon CPU + 高性能GPU |
| 数据分析/数据库 | CPU核心数、内存容量和速度、I/O性能 | Xeon CPU |
| 视频转码/处理 | 专用硬件单元、内存带宽 | Xeon CPU + QSV (Quick Sync Video) 或专用GPU |
解读“Intel Cup”的参数,不能孤立地看某一个数字,而应从系统级和应用级的视角出发:
(图片来源网络,侵删)
- 拆解:将“Cup”拆解为CPU、加速器、互连、软件四个部分。
- 定位:明确你的应用是AI训练、HPC还是数据分析。
- 匹配:根据应用需求,找到最关键的参数指标(如AI训练看BF16算力和内存带宽,HPC看FP64算力和CPU主频)。
- 权衡:在性能、功耗、成本和软件生态之间做出最佳平衡。
英特尔的“Intel Cup”战略本质上是通过硬件的异构整合和软件的统一,为开发者提供一个强大、灵活且易于使用的高性能计算平台,理解了其背后的架构和参数逻辑,就能更好地评估它是否适合你的业务需求。


