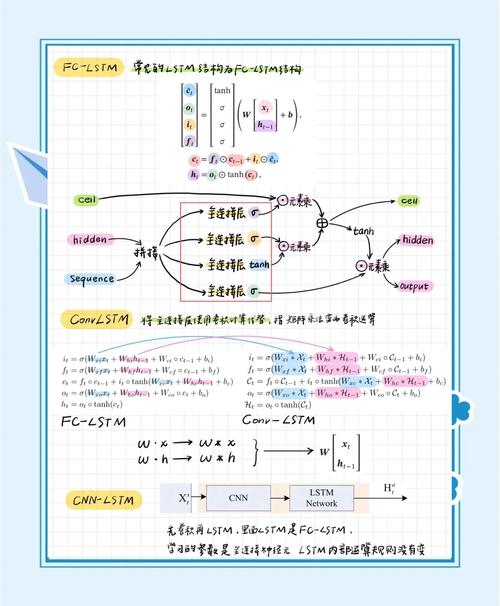
我们将参数分为几大类,以便更好地理解它们的作用:
(图片来源网络,侵删)
- 核心架构参数
- 状态与循环控制参数
- 正则化与 Dropout 参数
- 批量标准化与实现细节参数
- 高级用法示例
核心架构参数
这些参数定义了 LSTM 层的基本结构和计算方式。
units
- 类型:
int - 作用: 最重要的参数,定义了 LSTM 层中隐藏单元(hidden units)的数量,也就是输出向量的维度。
- 解释: 每个时间步,LSTM 层会输出一个维度为
units的向量,这个向量捕捉了到当前时间步为止的序列信息。units的值越大,模型的学习能力越强,但计算成本也越高,也更容易过拟合。 - 示例:
LSTM(units=128)表示该层有 128 个隐藏单元。
activation
- 类型:
strorcallable - 作用: 定义了内部激活函数。
- 解释: LSTM 内部有三个门(输入门、遗忘门、输出门)和一个细胞状态(cell state),这些门的计算通常使用 Sigmoid 函数(将值压缩到 0-1 之间),而细胞状态的更新则使用 Tanh 函数(将值压缩到 -1 到 1 之间),通常不需要修改这个参数。
- 默认值:
'tanh'(对细胞状态而言),门控机制默认使用sigmoid。
recurrent_activation
- 类型:
strorcallable - 作用: 定义了循环激活函数,即用于门控机制的激活函数。
- 解释: 专门用于输入门、遗忘门和输出门的计算,默认是
sigmoid,因为它非常适合作为门控信号(0 表示完全关闭,1 表示完全打开)。 - 默认值:
'sigmoid'
use_bias
- 类型:
bool - 作用: 是否使用偏置向量。
- 解释: 如果为
True(默认),LSTM 的计算中会加入一个可学习的偏置项,通常保留默认值即可。
kernel_initializer
- 类型:
strorcallable - 作用: 初始化权重矩阵
kernel(也称为W)的初始化器。 - 解释:
kernel是连接输入x_t和隐藏状态的权重矩阵,选择一个好的初始化器(如'glorot_uniform')有助于模型更快、更稳定地收敛。 - 默认值:
'glorot_uniform'
recurrent_initializer
- 类型:
strorcallable - 作用: 初始化循环权重矩阵
recurrent_kernel(也称为U)的初始化器。 - 解释:
recurrent_kernel是连接上一个时间步的隐藏状态h_{t-1}和当前时间步的权重矩阵,同样,良好的初始化很重要。 - 默认值:
'orthogonal'(正交初始化,在 RNN 中通常效果很好)
bias_initializer
- 类型:
strorcallable - 作用: 初始化偏置向量
bias的初始化器。 - 默认值:
'zeros'
状态与循环控制参数
这些参数控制了 LSTM 如何处理输入序列和其内部状态。
return_sequences
- 类型:
bool - 作用: 极其重要的参数,控制 LSTM 层的输出格式。
- 解释:
False(默认): 只返回最后一个时间步的隐藏状态h_T,输出形状为(batch_size, units),适用于序列分类(如情感分析)。True: 返回所有时间步的隐藏状态,输出形状为(batch_size, timesteps, units),适用于序列到序列的任务(如时间序列预测、机器翻译、命名实体识别)。
- 示例:
- 默认:
model.add(LSTM(64))-> 输出(batch_size, 64) - 返回序列:
model.add(LSTM(64, return_sequences=True))-> 输出(batch_size, timesteps, 64)
- 默认:
return_state
- 类型:
bool - 作用: 是否返回最终状态。
- 解释:
False(默认): 只返回输出(由return_sequences决定)。True: 返回一个列表,包含三个张量:[output, final_hidden_state, final_cell_state]。- 当
return_sequences=True且return_state=True时,输出为[all_hidden_states, final_hidden_state, final_cell_state]。
- 应用场景: 主要用于编码器-解码器(Encoder-Decoder)模型,其中编码器的最终状态需要传递给解码器作为其初始状态。
go_backwards
- 类型:
bool - 作用: 是否反向处理输入序列。
- 解释:
False(默认): 按时间顺序从t=0到t=T处理序列。True: 反向从t=T到t=0处理序列。
- 应用场景: 有时反向处理序列能取得更好的效果,例如在某些自然语言处理任务中。
stateful
- 类型:
bool - 作用: 是否保持状态(Stateful)。
- 解释:
False(默认): 每次处理一个 batch 的数据时,内部状态(hidden state 和 cell state)都会被重置为 0,这是最常见的模式。True: 不会重置状态,LSTM 会记住上一个 batch 的最后一个时间步的状态,并将其作为下一个 batch 的初始状态。
- 应用场景: 非常适合处理超长序列,或者需要连续建模的场景,如股票价格预测(希望模型记住昨天的状态来预测今天),使用此参数时,需要确保输入的 batch 大小是固定的,并且数据需要按顺序提供。
正则化与 Dropout 参数
这些参数用于防止模型过拟合。
dropout
- 类型:
float - 作用: 在输入到 LSTM 的循环连接上应用 Dropout。
- 解释: 这个 Dropout 是在时间步之间应用的,即在
h_{t-1}到h_t的路径上,它不应用于输入数据x_t本身,也不应用于最后的输出。 - 默认值:
0(不使用)
recurrent_dropout
- 类型:
float - 作用: 在 LSTM 内部的循环连接上应用 Dropout。
- 解释: 这是在 LSTM 内部的循环连接上(即权重矩阵
U的连接)应用的 Dropout,这是对循环网络进行正则化的一个非常有效的方法。 - 默认值:
0(不使用)
批量标准化与实现细节参数
batch_input_shape
- 类型:
tuple (batch_size, timesteps, input_dim) - 作用: 指定输入张量的形状。
- 解释: 当模型的第一层是 LSTM 时,可以使用此参数来定义输入数据的维度。
batch_size设为None,则表示可以使用可变大小的 batch,更推荐使用Input层来定义输入形状。
unroll
- 类型:
bool - 作用: 是否展开循环计算。
- 解释:
False(默认): 使用优化的循环内核(CuDNN LSTM if available),计算效率高,适合长序列。True: 将循环展开为固定大小的循环神经网络,这可以加快某些短序列的计算速度,但会消耗大量内存,并且只能处理固定长度的序列。
- 默认值:
False。通常不要手动设置为True。
高级用法示例
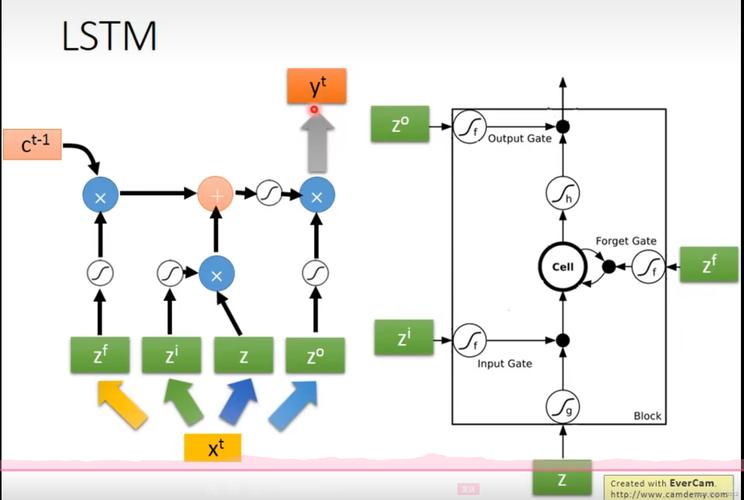
示例 1: 多层 LSTM (Stacked LSTM)
为了构建更强大的模型,可以将多个 LSTM 层堆叠起来,关键点:除了最后一层,所有中间层的 return_sequences 都必须设为 True。
(图片来源网络,侵删)
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, Dense, Input model = Sequential() # 第一层 LSTM,必须指定输入形状 model.add(Input(shape=(timesteps, input_features))) model.add(LSTM(units=64, return_sequences=True)) # 返回所有时间步的输出 model.add(LSTM(units=32)) # 最后一层,只返回最后一个时间步的输出 model.add(Dense(units=1, activation='sigmoid')) # 输出层 model.summary()
示例 2: 编码器-解码器模型
这需要用到 return_state=True 来获取编码器的最终状态。
from tensorflow.keras.models import Model from tensorflow.keras.layers import Input, LSTM, Dense # --- 编码器 --- encoder_inputs = Input(shape=(None, num_encoder_tokens)) encoder = LSTM(latent_dim, return_state=True) _, state_h, state_c = encoder(encoder_inputs) # 'encoder_outputs' 在这里我们不使用,所以用 _ 忽略 # 将最终状态合并为一个 "encoder_states" 向量 encoder_states = [state_h, state_c] # --- 解码器 --- decoder_inputs = Input(shape=(None, num_decoder_tokens)) # 解码器在训练时需要接收完整的输入序列,return_sequences=True # 解码器在预测时是逐个生成 token,因此我们还需要返回状态 decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True) decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states) decoder_dense = Dense(num_decoder_tokens, activation='softmax') decoder_outputs = decoder_dense(decoder_outputs) # --- 定义完整模型 --- model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
总结表格
| 参数名 | 类型 | 默认值 | 作用简述 |
|---|---|---|---|
units |
int |
(必需) | 隐藏单元的数量,即输出维度 |
return_sequences |
bool |
False |
是否返回所有时间步的输出(关键参数) |
return_state |
bool |
False |
是否返回最终隐藏状态和细胞状态 |
stateful |
bool |
False |
是否跨 batch 保持状态 |
dropout |
float |
0 |
在时间步之间的输入连接上应用 Dropout |
recurrent_dropout |
float |
0 |
在 LSTM 内部的循环连接上应用 Dropout |
go_backwards |
bool |
False |
是否反向处理输入序列 |
activation |
str/callable |
'tanh' |
内部激活函数(细胞状态) |
recurrent_activation |
str/callable |
'sigmoid' |
循环激活函数(门控) |
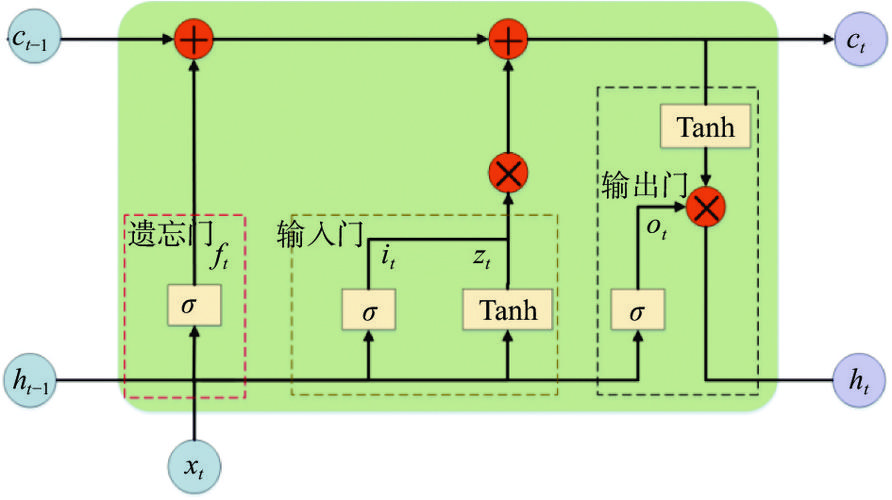
掌握这些参数,你就可以灵活地配置 tf.keras.layers.LSTM 来应对各种复杂的序列建模任务了。
(图片来源网络,侵删)


