下面我们分步拆解。

核心公式:参数量的构成
一个标准的 Transformer 模型(以 Decoder-only 的 GPT 类模型为例)主要由两部分组成:
- Transformer 层:这是模型的核心,包含了自注意力机制和前馈神经网络,模型由多个这样的层堆叠而成。
- 输出层:通常是一个线性层,用于将最终的隐藏状态映射到词汇表大小,以生成预测的概率分布。
总参数量 ≈ (Transformer 层的参数量 × N) + 输出层的参数量
N 是模型的层数。
核心超参数
理解参数量,首先要理解几个关键的超参数:
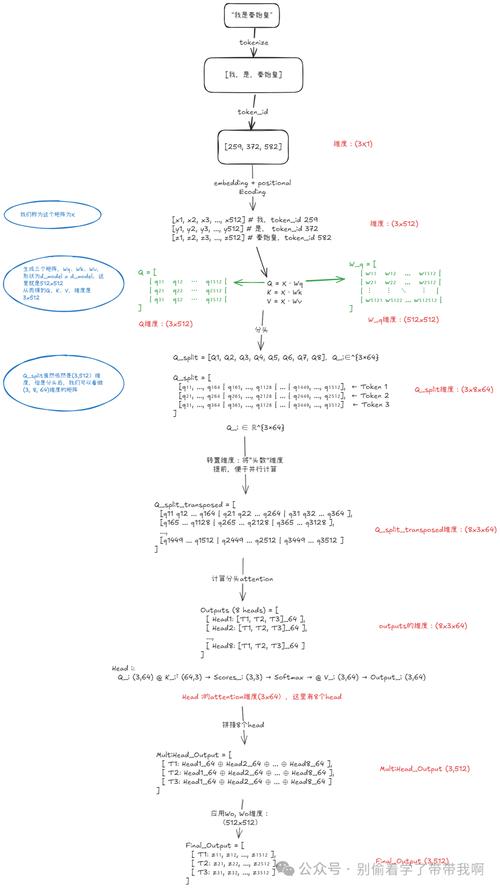
N: 层数,模型堆叠了多少个 Transformer 层,GPT-3 有 96 层。d_model: 隐藏层维度 / 嵌入维度,这是模型内部处理数据向量的维度,维度越高,模型表达能力越强,参数量也越大,GPT-3 的d_model是 12288。d_ff: 前馈网络维度,这是 Transformer 层内部前馈神经网络的隐藏层维度,通常设置为d_model的 4 倍(这是一个经验值,为了在计算上更高效)。h: 注意力头数,多头注意力机制将d_model分成h个“头”,每个头独立学习注意力模式。h必须能整除d_model,GPT-3 的h是 96。- `V词汇表大小**,模型输出层的大小,决定了模型能生成多少个不同的词。
参数量计算详解
我们以一个标准的 Transformer Decoder Block 为例,计算其参数量。
A. 嵌入层
-
词嵌入层:
- 参数量 =
V × d_model - 这是一个巨大的查找表,将每个词 ID 映射为一个
d_model维的向量。
- 参数量 =
-
位置编码层:
- 参数量 =
max_sequence_length × d_model - 位置编码通常是固定的、可学习的或正弦/余弦函数生成的,如果是可学习的,其参数量与词嵌入层类似,但通常较小,因为
max_sequence_length远小于V,在粗略估算时,有时可以忽略。
- 参数量 =
B. N 个 Transformer 层
这是参数量的主要来源,每一层都包含两个核心子层:多头自注意力 和 位置前馈网络。
-
多头自注意力层:
- 输入/输出投影层: 在注意力计算前后,需要将输入向量从
d_model维投影到d_k(或d_v) 维,然后再投影回来。- 有 3 个权重矩阵用于 Q, K, V 的投影,每个的维度都是
d_model × d_k(d_k = d_model / h)。 - 有 1 个权重矩阵用于输出投影,维度是
d_model × d_model。 - 总参数量 ≈
3 * d_model * d_model + d_model * d_model = 4 * d_model²(d_k约等于d_model)。
- 有 3 个权重矩阵用于 Q, K, V 的投影,每个的维度都是
- 偏置项: 每个线性层通常还有偏置项,参数量为
4 * d_model,相比d_model²,可以忽略。
- 输入/输出投影层: 在注意力计算前后,需要将输入向量从
-
位置前馈网络层:
- 它由两个线性层组成。
- 第一个线性层:
d_model → d_ff,参数量为d_model * d_ff。 - 第二个线性层:
d_ff → d_model,参数量为d_ff * d_model。 - 总参数量 =
d_model * d_ff + d_ff * d_model = 2 * d_model * d_ff。 - 因为
d_ff通常是4 * d_model,所以这个层的参数量约为2 * d_model * (4 * d_model) = 8 * d_model²。
-
层归一化和:
- 每个子层(注意力层和FFN层)后都有一个层归一化,它有可学习的缩放参数 和偏移参数 ,维度都是
d_model。 - 每个层归一化的参数量为
2 * d_model。 - 一个 Transformer 层有两个层归一化,所以是
4 * d_model,相比d_model²,可以忽略。
- 每个子层(注意力层和FFN层)后都有一个层归一化,它有可学习的缩放参数 和偏移参数 ,维度都是
单个 Transformer 层的参数量估算:
Layer_Params ≈ 4 * d_model² (注意力) + 8 * d_model² (FFN) = 12 * d_model²
N 个 Transformer 层的总参数量:
N_Layer_Params ≈ N * 12 * d_model²
C. 输出层
- 最终的线性投影层:
- 它将最后一层的
d_model维输出映射到词汇表大小V。 - 参数量 =
d_model * V
- 它将最后一层的
总参数量估算公式
综合以上所有部分,一个 Decoder-only Transformer(如 GPT)的总参数量可以估算为:
Total_Params ≈ (词嵌入层) + (N个Transformer层) + (输出层) Total_Params ≈ (V × d_model) + (N × 12 × d_model²) + (d_model × V) Total_Params ≈ 2 × V × d_model + N × 12 × d_model²
重要观察:
- 当
d_model很大时(现代大模型通常如此),N × d_model²项会远远大于V × d_model项。模型参数量主要由层数和隐藏层维度的平方决定,词表大小V对总参数量的影响相对较小。
实际案例计算
让我们用这个公式来估算一下几个著名模型的参数量。
案例 1: GPT-3 (175B 版本)
N= 96d_model= 12288V≈ 50257 (词汇表大小)d_ff= 4 * 12288 = 49152
计算:
- Transformer 层参数:
96 * 12 * (12288)² = 96 * 12 * 150,994,944 ≈ 173.8 B - 嵌入层 + 输出层参数:
2 * 50257 * 12288 ≈ 1.24 B
总计: 8 B + 1.24 B ≈ 175 B
这个估算与官方公布的 1750 亿参数非常吻合!
案例 2: BERT-Large
- 架构: Encoder-only
N= 24d_model= 1024V≈ 30522
计算:
- Transformer 层参数:
24 * 12 * (1024)² = 24 * 12 * 1,048,576 ≈ 301.0 M - 嵌入层 + 输出层参数:
2 * 30522 * 1024 ≈ 62.5 M
总计: 0 M + 62.5 M ≈ 363.5 M
BERT-Large 的实际参数量约为 340M,我们的估算非常接近,差异可能源于我们忽略的层归一化参数以及一些其他细节。
不同架构的参数量差异
- Encoder-only (如 BERT): 主要用于理解任务,参数量计算与上述类似。
- Decoder-only (如 GPT, LLaMA, PaLM): 主要用于生成任务,参数量计算如上所述,是目前大语言模型的主流架构。
- Encoder-Decoder (如 T5, 原始 Transformer): 包含一个 Encoder 和一个 Decoder。
- 总参数量 ≈ Encoder_Params + Decoder_Params
Encoder_Params ≈ V_emb × d_model + N_enc × 12 × d_model²Decoder_Params ≈ V_emb × d_model + N_dec × 12 × d_model² + d_model × V_vocab- 这种架构的参数量通常比同等规模的纯 Encoder 或纯 Decoder 模型要大。
| 模型类型 | 关键超参数 | 参数量主导项 | 估算公式 (简化) |
|---|---|---|---|
| Decoder-only (GPT类) | N (层数), d_model (维度) |
N * d_model² |
~ 12 * N * d_model² |
| Encoder-only (BERT类) | N (层数), d_model (维度) |
N * d_model² |
~ 12 * N * d_model² |
| Encoder-Decoder (T5类) | N_enc, N_dec, d_model |
(N_enc + N_dec) * d_model² |
~ 12 * (N_enc + N_dec) * d_model² |
核心要点:
要估算 Transformer 的参数量,层数 N 和隐藏层维度 d_model 是最重要的两个指标,参数量与它们的乘积 N * d_model² 成正比,这是为什么增加模型规模主要通过“加深”(增加 N)和“加宽”(增加 d_model)来实现。


