下面我将详细介绍 Hadoop Streaming 的核心参数、工作原理以及一个完整的 Python 示例。
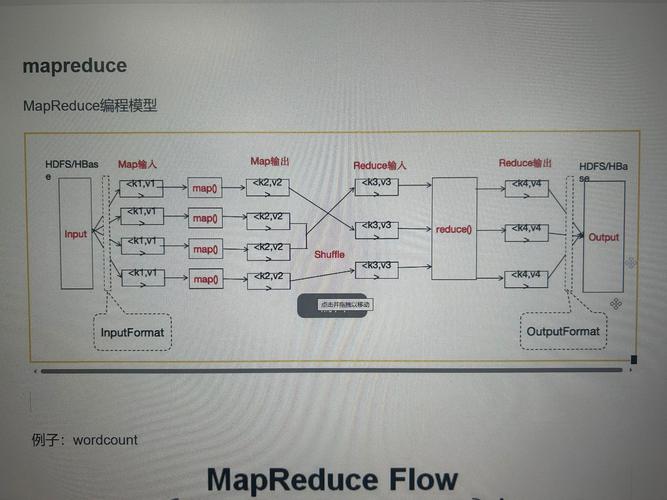
核心工作原理
Hadoop Streaming 的核心思想是利用 Unix/Linux 的标准输入和标准输出。
-
Mapper:
- Hadoop 会为每个 Mapper 任务启动一个指定的脚本(
my_mapper.py)。 - Hadoop 将输入文件的每一行作为数据,通过标准输入 发送给这个脚本。
- 你的 Mapper 脚本处理数据后,将键值对(通常是
tab分隔的)通过标准输出 输出。 - H Streaming 会捕获这些标准输出,并将它们发送给 Reducer。
- Hadoop 会为每个 Mapper 任务启动一个指定的脚本(
-
Reducer:
- Hadoop 会为每个 Reducer 任务启动一个指定的脚本(
my_reducer.py)。 - Hadoop 会将所有 Mapper 的输出根据 Key 进行排序和分组,然后将每个 Key 的所有 Value 集合,通过标准输入 发送给 Reducer 脚本。
- 你的 Reducer 脚本处理数据后,将最终结果通过标准输出 输出到 HDFS。
- Hadoop 会为每个 Reducer 任务启动一个指定的脚本(
关键点:Mapper 和 Reducer 脚本都遵循 "读入标准输入,写出标准输出" 的原则,键值对之间默认用制表符(\t)分隔。
主要参数详解
Hadoop Streaming 的参数通过 -D 或 --config 设置,或者通过 -files, -archives 等传递资源。
基础执行参数
这些参数用于指定 Mapper 和 Reducer 脚本。
-
-input <path>- 说明:指定输入文件的路径,可以是 HDFS 上的目录或文件。
- 示例:
-input /user/hadoop/input
-
-output <path> (图片来源网络,侵删)
(图片来源网络,侵删)- 说明:指定输出目录的路径,该目录在作业执行前不能存在。
- 示例:
-output /user/hadoop/output
-
-mapper <executablename or command>- 说明:指定 Mapper 脚本或命令,可以是本地路径(需要配合
-files),也可以是 HDFS 上的路径。 - 示例:
-mapper my_mapper.py
- 说明:指定 Mapper 脚本或命令,可以是本地路径(需要配合
-
-reducer <executablename or command>- 说明:指定 Reducer 脚本或命令。
- 示例:
-reducer my_reducer.py
-
-file <file>- 说明:将本地文件(如你的 Python 脚本)复制到 Hadoop 集群的每个 TaskTracker 节点上,使其在任务执行时可用,如果你的 Mapper 或 Reducer 脚本在同一目录下,需要用此参数打包。
- 示例:
-file mapper.py -file reducer.py
数据格式和分隔符参数
这是最常用的一组参数,用于自定义输入和输出的格式。
-
-inputformat <class>- 说明:指定输入格式类,默认是
org.apache.hadoop.mapred.TextInputFormat,它按行读取文件,你可以使用其他格式,如KeyValueTextInputFormat(按 Key-Value 对读取,分隔符由mapred.text.keyvalue.separator指定)。
- 说明:指定输入格式类,默认是
-
-outputformat <class>- 说明:指定输出格式类,默认是
org.apache.hadoop.mapred.TextOutputFormat,它将键值对用制表符分隔后写入文件。
- 说明:指定输出格式类,默认是
-
-inputfieldmarkermarker <character>- 说明:已过时,请使用
-D stream.map.input.field.separator和-D stream.map.output.field.separator。
- 说明:已过时,请使用
-
-D stream.map.input.field.separator=<character>- 说明:非常重要,指定 Mapper 输入的分隔符,默认是换行符
\n(因为 TextInputFormat 是按行读取的),如果你的输入文件不是按行分隔的,而是用其他字符(如逗号)分隔的,你需要设置这个参数。 - 示例:
-D stream.map.input.field.separator=,
- 说明:非常重要,指定 Mapper 输入的分隔符,默认是换行符
-
-D stream.map.output.field.separator=<character>- 说明:非常重要,指定 Mapper 输出到 Reducer 的键值对之间的分隔符,默认是制表符
\t。 - 示例:
-D stream.map.output.field.separator=,
- 说明:非常重要,指定 Mapper 输出到 Reducer 的键值对之间的分隔符,默认是制表符
-
-D stream.reduce.input.field.separator=<character>- 说明:指定 Reducer 输入的分隔符,通常与
stream.map.output.field.separator保持一致,默认也是制表符\t。
- 说明:指定 Reducer 输入的分隔符,通常与
-
-D stream.reduce.output.field.separator=<character>- 说明:指定 Reducer 最终输出的键值对之间的分隔符,默认是制表符
\t。
- 说明:指定 Reducer 最终输出的键值对之间的分隔符,默认是制表符
作业控制参数
-
-partitioner <class>- 说明:指定分区器类,决定如何将 Mapper 的输出分配给不同的 Reducer,默认是
org.apache.hadoop.mapred.lib.HashPartitioner,它根据 Key 的哈希值进行分区,如果你想自定义分区逻辑(让某些 Key 始终去同一个 Reducer),可以实现自己的分区器类。
- 说明:指定分区器类,决定如何将 Mapper 的输出分配给不同的 Reducer,默认是
-
-combiner <executablename>- 说明:指定 Combiner 脚本,Combiner 在 Map 端运行,用于对本地输出的数据进行预聚合,以减少网络传输和数据量到 Reducer 的数据量,Combiner 的逻辑通常和 Reducer 相同。
- 示例:
-combiner my_reducer.py
-
-cmdenv <name=value>- 说明:为 Mapper 和 Reducer 任务设置环境变量。
- 示例:
-cmdenv "LD_LIBRARY_PATH=/usr/local/lib"
资源分发参数
-
-files <comma-separated list of files>- 说明:
-file的复数形式,可以一次性指定多个需要分发的文件,这些文件会被解压到任务工作目录,可以通过文件名直接访问。 - 示例:
-files /path/to/config.txt,/path/to/mylib.jar
- 说明:
-
-archives <comma-separated list of archives>- 说明:分发归档文件,如
.tar.gz,.zip,.jar,归档文件会被解压到任务工作目录,可以通过符号链接访问其内容。 - 示例:
-archives /path/to/data.zip#data_link,解压后,会创建一个名为data_link的符号链接指向解压后的目录。
- 说明:分发归档文件,如
Python 示例
下面是一个经典的 Word Count 例子,展示如何使用 Hadoop Streaming 和 Python 脚本。
准备 Mapper 脚本 (mapper.py)
这个脚本负责读取输入的每一行,将其转换为小写,然后分割成单词,最后输出每个单词和 1。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
# 读取标准输入的每一行
for line in sys.stdin:
# 去除首尾的空白字符(如换行符)
line = line.strip()
# 将行转换为小写
line = line.lower()
# 分割单词
words = line.split()
# 遍历每个单词,输出 单词\t1
for word in words:
# 使用制表符 \t 作为分隔符
print(f"{word}\t1")
准备 Reducer 脚本 (reducer.py)
这个脚本负责读取 Mapper 的输出(格式为 word\t1),然后对每个单词的计数值进行求和。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
# 当前正在处理的单词
current_word = None
current_count = 0
word = None
# 读取标准输入的每一行
for line in sys.stdin:
# 去除首尾的空白字符
line = line.strip()
# 分割行,得到单词和计数值
# 默认情况下,Hadoop Streaming 会用制表符 \t 分割
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
# 如果计数值不是数字,则跳过此行
continue
# 如果是处理同一个单词,累加计数值
if current_word == word:
current_count += count
# 如果是新的单词
else:
# 如果当前单词不为空(即不是第一个单词),则打印上一个单词的总和
if current_word:
print(f"{current_word}\t{current_count}")
# 重置当前单词和计数值
current_word = word
current_count = count
# 处理最后一个单词
if current_word == word:
print(f"{current_word}\t{current_count}")
提交 Hadoop Streaming 作业
假设你的输入文件在 /user/hadoop/input/,你希望将结果输出到 /user/hadoop/output/,你的 mapper.py 和 reducer.py 都在当前目录。
# 1. 确保 Hadoop 服务正在运行
# start-dfs.sh
# start-yarn.sh
# 2. 创建 HDFS 输入目录并上传一个测试文件
hdfs dfs -mkdir -p /user/hadoop/input
hdfs dfs -put my_test.txt /user/hadoop/input/
# 3. 赋予 Python 脚本执行权限(可选,但推荐)
chmod +x mapper.py
chmod +x reducer.py
# 4. 运行 Hadoop Streaming 作业
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar \
-input /user/hadoop/input \
-output /user/hadoop/output \
-mapper ./mapper.py \
-reducer ./reducer.py \
-file ./mapper.py \
-file ./reducer.py \
-D stream.map.output.field.separator="\t" \
-D stream.reduce.output.field.separator="\t"
# 参数解释:
# -jar ...: 指定 hadoop-streaming 的 jar 包路径(* 会匹配版本号)
# -input ...: HDFS 输入路径
# -output ...: HDFS 输出路径
# -mapper ./mapper.py: 本地 Mapper 脚本
# -reducer ./reducer.py: 本地 Reducer 脚本
# -file ...: 将本地脚本文件分发到集群
# -D ...: 显式指定键值对分隔符为制表符,这是 Python 脚本期望的格式
# 5. 查看结果
hdfs dfs -cat /user/hadoop/output/part-00000
常见问题与最佳实践
- 性能问题:相比于 Java MapReduce,Hadoop Streaming 因为进程启动和数据序列化/反序列化的开销,性能通常稍差,对于 CPU 密集型任务,可以考虑使用 Cython 或 PyPy 加速你的 Python 脚本。
- 分隔符一致性:确保你的脚本内部处理分隔符的逻辑与通过
-D参数设置的分隔符完全一致,这是最常见的错误来源。 - 错误处理:在 Mapper 和 Reducer 脚本中添加适当的错误处理(如
try-except),以防意外输入导致脚本崩溃。 - 调试:可以先在本地测试你的 Mapper 和 Reducer 脚本,用
cat input.txt | python mapper.py | sort | python reducer.py来模拟整个流程,因为 Hadoop 会自动对 Mapper 的输出进行排序。 - 新版 Hadoop (YARN):上述命令和参数同样适用于 Hadoop 2.x 及以上版本(使用 YARN 作为资源管理器),因为
hadoop-streaming.jar是向后兼容的。


